Aurelie Giraud

Data Scientist & Data Product Manager
LinkedIn | Blog
Hi 👋 I'm Lily,
Data Scientist, aspiring storyteller, and writer - on a mission to democratize Analytics. It all started during my Master's degree when I discovered a passion for Statistics and Experimental Design. Shortly after - as a project manager, I learned how businesses work and how to communicate with stakeholders from disparate backgrounds. Ultimately I realized that I get the most joy from making a business impact based on data, analytics, and automation. From there, I decided to drop everything and start over to become a Data Scientist. Today, when I'm not coding, you can find me writing blogs on how to apply Data Science to solve business challenges and self-growth.
Revenue Prediction with ANOVA and Linear Regression.
✅ Business Case
In this project, we attempt to create a model to target future relevant customers among the current portfolio of a bank and using the revenue data of their parents. Two approaches are tested: ANOVA one-way and Multiple Linear Regression.
📉 Dataset
This project was completed as a part of the Data Analyst nanodegree displayed by Openclassrooms. The dataset is therefore provided by the platform as a part of the program.
📒 Repository
The repository is available on GitHub. It describes how to apply ANOVA and Multiple Linear Regression Models using the following steps:
- Collection & Exploration
In that step, we collect, summarize and discuss the relevance of the data collected for the modeling. This step is critical to ensure the relevance of the model.
- Features Engineering
Here we are creating the relevant explanatory variables. For example, we use conditional probabilities to segment the portfolio into class of revenues and extract the likelihood of a customer (children) to fall into the same class of revenue than its parents.
- Modelling
Finally, we are attempting to predict the customer’s revenues using ANOVA-one way and Multiple Linear Regressions models.
🎯 Key take-away
1. Explanatory Variables
We start the analytics by evaluating the diversity of income across a selection of 5 countries, using the Lorenz curve and Gini Index.
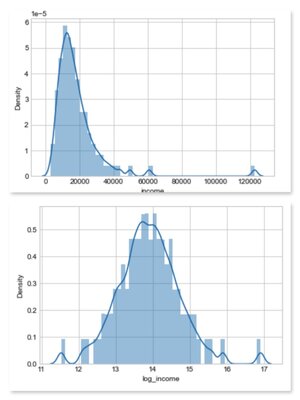
- Log-Income
Before to start we need to perform a log-transformation of the variable income because the distribution highly skewed to the right - meaning that there are some very high incomes. The transformation allows the distribution to follow a bell shape a.k.a Gaussian-like distribution which is ideal for modelling.
✅ Here is an example of the effect of the log-transformation on the distribution of income for a given country.
- Lorenz curve & Gini Index
The Lorenz concentration curve is a way to represent the distribution function of a variable X. It is used in particular in economics to measure inequalities in the possession of wealth. We will use it here to assess inequalities in terms of the distribution of incomes among the group of countries selected. The furthest the Lorenz curve is from the first bisector line, the more inequalities of revenue in the given country.
def lorenz_curve(X):
lorenz = np.cumsum(np.sort(X['income'])) / X['income'].sum()
lorenz = np.append([0],lorenz)
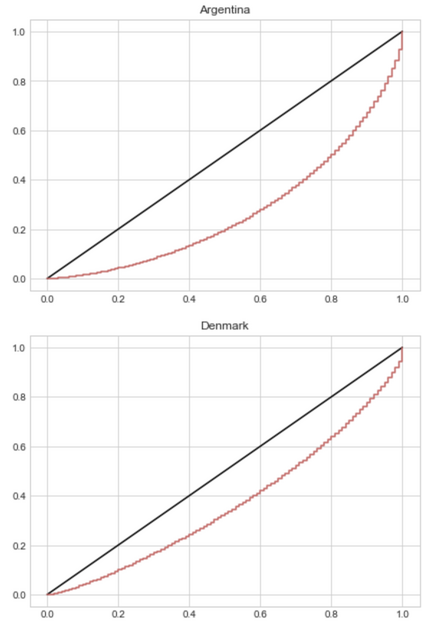
✅ In the example above, we can see here that there are more inequalities in Argentina than in Denmark.
The Gini index represents the area between the Lorenz curve and the first bisector line. It is a good metric to summarize the information from the Lorenz curve. The smallest the Gini Index, the least inequalities in the given country.
✅ In the example above, we can see that Denmark and Iceland are the countries with the least inequalities in our given selection.
- Class of revenue
At that stage, we have two of the three desired explanatory variables: the average income and the gini index for each given country. We only lack now the income class of an individual’s parents to move forward into the prediction. The idea is to use this variable to predict the probability for an individual to fall into the same class of income than its parents - this will bring us closer to predict the revenue of an individual.
We suppose here that we associate with each individual a unique class regardless of the number of parents. We are going to simulate this information using a coefficient (specific to each country) measuring a correlation between the income of an individual and the income of its parents. This coefficient will be called the elasticity coefficient or relative IGM in income. It measures the intergenerational income mobility.
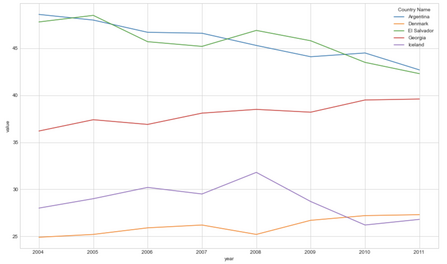
✅ Here is an example of visualization for the country of Panama: the chart represents the conditionnal probability for a child to fall into the income class of its parents. We can see in that case, that the earnings of (adult) children are dependent on the income of their parents. It means, that a child born in a family with low revenue in Panama, has a higher probability to also have low revenue when he will be adult.

2. TEST Model 1: ANOVA
1. PERFORMANCES
ANOVA is applied in this project to verify the effect of a qualitative variable (country’s name) on a quantitative variable (income).
# ANOVA 1-way with log-income values
model = ols('log_income ~ C(name)',data = df).fit()
table = sm.stats.anova_lm(model,type=2)
anova_table(table)

Using the log-income help to improve the model: Eta-squared is around 0.76 vs 0.47 for the model based on the income. It is still relatively low (we generally aim for at least 90%), probably because there are others important variables to explain the variability of incomes. The model sum of square is about 3 times higher than the error sum of square, which indicates that the country name is a pretty good parameter to explained and predict the income:
-
Variability explained by the country equals = 7.975793e+06
-
Variability explained by other factors not included in the model = 2.555139e+06
The MSE is high for the predictor (country name) but much lower than with the previous model. The MSE for the residual is around 1, which indicates again that the model is performing better than the previous model to fit and predict the data but could be improved. p-value « alpha risk (5%), meaning that at least one group is different than the rest (so that the income depend on the country).
✅ The variability of income can be partly explained by the country we are observing, meaning that if we are observing the income from Angola or from Denmark, we can expect the income to be different.
There are certain assumptions that needs to be verified for ANOVA model:
2. NORMALITY
The assumption of normality is tested on the residuals of the model. It can be verified using histograms and Q-Q plot, or using statistical tests such as Shapiro-Wilk or Anderson & Darling. The violations of normality, continuing with ANOVA is generally ok if you have a large sample size.
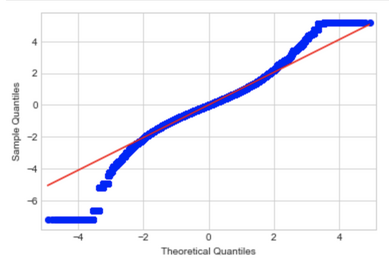
✅ Q-Q plot: The distribution is relatively close to a normal distribution but has some fat tails to the right and left and is slightly in S shape.
Because we have a sample size > 5000, the Shapiro test is actually not ideal (For N > 5000 the W test statistic is accurate but the p-value may not be). We can use the Anderson and Darling test or the non-parametric test Kolmogoriv and Smirnov.
Anderson & Darling Hypothesis:
H0 = The sample is drawn from a population that follows a particular distribution, here the Normal distribution. H1 = The sample is NOT drawn from a population that follows the Normal distribution. If the returned statistic is larger than these critical values then for the corresponding significance level, the null hypothesis that the data come from the chosen distribution can be rejected.
st.anderson(model2.resid,dist='norm')
AndersonResult(statistic=10248.77901675459, critical_values=array([0.576, 0.656, 0.787, 0.918, 1.092]), significance_level=array([15. , 10. , 5. , 2.5, 1. ]))
✅ The statistic value is largely above any of the critical values, meaning that we are in the zone where H0 can be rejected. The residuals are not following a Normal distribution.
3. HOMOGENEITY
The assumption of homogeneity of variance is an assumption of the independent samples t-test and ANOVA stating that all comparison groups have the same variance. The independent samples t-test and ANOVA utilize the t and F statistics respectively, which are generally robust to violations of the assumption as long as group sizes are equal. Equal group sizes may be defined by the ratio of the largest to smallest group being less than 1.5 source
One method for testing this assumption is the Levene’s test of homogeneity of variances. If the data is not following a normal distribution Levene’s test is preferred over the Barlett’s test.
# Test homoscedasticity by comparing the group (= countries) with dependent variable = log_income
pg.homoscedasticity(df, dv='log_income', group='name',method='levene')
✅ The test revealed that the condition of homogeneity of variances is not respected. Numerous investigations have examined the effects of variance heterogeneity on the empirical probability of a Type I error for the analysis of variance (ANOVA) F-test and the prevailing conclusion has been that when sample sizes are equal, the ANOVA is robust to variance heterogeneity. However, we should not assumed that the ANOVA F-test is always robust to variance heterogeneity when sample sizes are equal source In this case study, we do not have strictly the same size for each groups however the differences are very small (« 1,5 between the largest and the smallest group), so we might consider our model robust to the violation of this assumption. Alternatively, there are two tests that we could run that are applicable when the assumption of homogeneity of variances has been violated: (1) Welch or (2) Brown and Forsythe test.
4. INDEPENDENCE
Independence of residuals is commonly referred to as the total absence of autocorrelation. Even though uncorrelated data does not necessarily imply independence, one can check if random variables are independent if their mutual information tends to 0. We can use a Durbin and Watson test which calculates the Durbin-Watson statistic. The test will output values between 0 and 4. Here are how to interpret the results of the test:
-
The closer to 2, the more evidence for no autocorrelation.
-
The closer to 0 the statistic, the more evidence for positive serial correlation.
-
The closer to 4, the more evidence for negative serial correlation.
df.durbin_watson(model2bis.resid, axis=0)
>> Output: 0.0004796685172174014
✅ The result suggest a positive autocorrelation in the residuals. So the condition of independance is not verified.
💥 All in all, none of the conditions necessary for applying an ANOVA are verified here. So, even tough the model retrieved some relatively good performances we can not rely on it. Let’s try to build another model based on multiple linear regression.
3. TEST Model 2: Multiple Linear Regression
1. PERFORMANCES
In this project we have tested different combination of the explanatory variables in order to find the best model. Ultimately, the model based on the gini index, the log-average income and the parent’s class, is the one providing the best performances to predict the income. It explains 81% of the variances, meaning that only 19% remains unexplained and due to others factors ike fx. chance, efforts,…
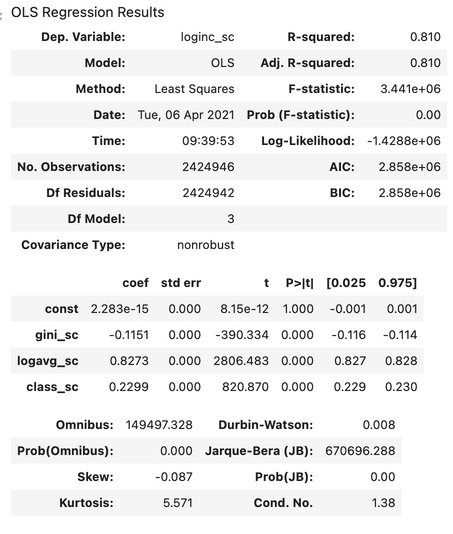
Similarly to the ANOVA we must verified the conditions of normality, homogeneity and independance for the linear model to be valid. In addition, we must observed a linear relationship between the dependent and the independent variables and ideally, the absence of multicollinearity.
💥 We have previously established that the conditions of normality, homogeneity and independence were not respected. Let’s describe further how to check the collinearity condition.
2. MULTICOLLINEARITY
We can check the existence of collinearity between two or more variables with the Variance Inflation Factor (VIF). It’s a measure of colinearity among predictor variables within a multiple regression. A rule of thumb for interpreting the variance inflation factor:
- 1 = not correlated.
- Between 1 and 5 = moderately correlated.
- Greater than 5 = highly correlated.
The more VIF increases, the less reliable your regression results are going to be. In general, a VIF above 10 indicates high correlation and is cause for concern. Some authors suggest a more conservative level of 2.5 or above source.
# For each X, calculate VIF and save in dataframe
x5 = add_constant(X5)
vif = pd.DataFrame()
vif["VIF Factor"] = [variance_inflation_factor(x5.values, i) for i in range(x5.shape[1])]
vif["features"] = x5.columns
vif.round(1) #inspect results
✅ The test revealed that there is no collinearity between the features of the model.
3. CONCLUSIONS
All in all, the 2 models tested retrieved some good performances in terms of predictions BUT they can not be fully trusted as they rely on non-verified conditions. Moving forward we could try for example to apply other types of regression models. More to discover here